篇首语:本文由编程笔记#小编为大家整理,主要介绍了Springboot系列(三十二):Springboot集成 kafka(环境搭建+演示)|超级详细,建议收藏相关的知识,希望对你有一定的参考价值。
👨🎓 作者:bug菌
🎉简介:在CSDN、掘金等社区优质创作者,全网合计6w粉+,对一切技术都感兴趣,重心偏java方向,目前运营公众号[猿圈奇妙屋],欢迎小伙伴们的加入,一起秃头。
🚫特别声明:原创不易,转载请附上原文出处链接和本文声明,谢谢配合。
🙏版权声明:文章里可能部分文字或者图片来源于互联网或者百度百科,如有侵权请联系bug菌处理。

嗨,家人们,我是bug菌呀,我又来啦。今天我们来聊点什么咧,OK,接着为大家更《springboot零基础入门教学》系列文章吧。希望能帮助更多的初学者们快速入门!
小伙伴们在批阅文章的过程中如果觉得文章对您有一丝丝帮助,还请别吝啬您手里的赞呀,大胆的把文章
点亮👍吧,您的点赞三连(
收藏⭐️+关注👨🎓+留言📃)就是对bug菌我创作道路上最好的鼓励与支持😘。时光不弃🏃🏻♀️,创作不停💕,加油☘️
上一期,我是带着大家入门了springboot集成RabbitMq,今天我再来一期kafka的零基础教学吧。不知道大家对kafka有多少了解,反正我就是从搭建开始,然后再加一个简单演示,这就算是带着大家了个门哈,剩下的我再后边慢慢出教程给大家说。
演示环境:idea2019.3 + springboot 2.3.1REALSE + windows10 + kafka
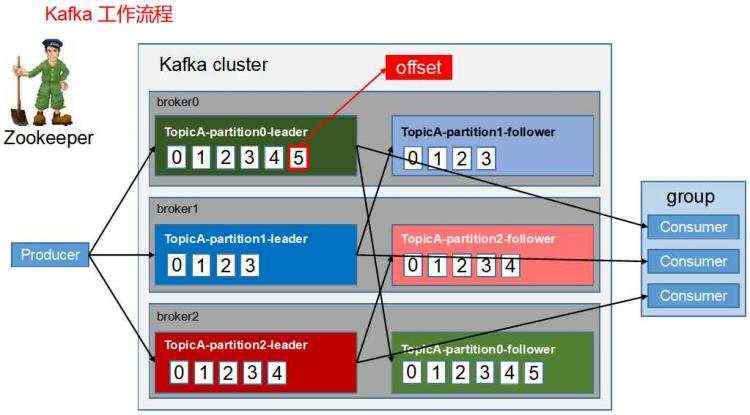
kafka是linkedin开源的分布式发布-订阅消息系统,目前归属于Apache的顶级项目。主要特点是基于pull模式来处理消息消费,追求高吞吐量,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统。
一开始的目的是日志的收集和传输。0.8版本开始支持复制,不支持事务,对消息的丢失,重复,错误没有严格要求 适用于产生大量数据的互联网服务的数据收集业务。在廉价的服务器上都能有很高的性能,这个主要是基于操作系统底层的pagecache,不用内存胜似使用内存。
综上所述,kafka是一款开源的消息引擎系统(消息队列/消息中间件) 分布式流处理平台。
下载地址:https://www.apache.org/dyn/closer.cgi?path=/kafka/3.1.0/kafka_2.13-3.1.0.tgz
下载完后是这么个东西:


进入config目录,修改server.properties文件,把 log.dirs的值改成 ./logs

在你的安装目录下的bin\\windows目录上直接输入cmd然后回车。

执行命令:输入
kafka-server-start.bat ../../config/server.properties

然后可以看到控制台启动报错:

可以看到,kafka还依赖于zookeeper。所以我们接下来再安装zookeeper,启动zookeeper后再启动kafka试试。
先下载zookeeper,下载地址:https://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.7.0
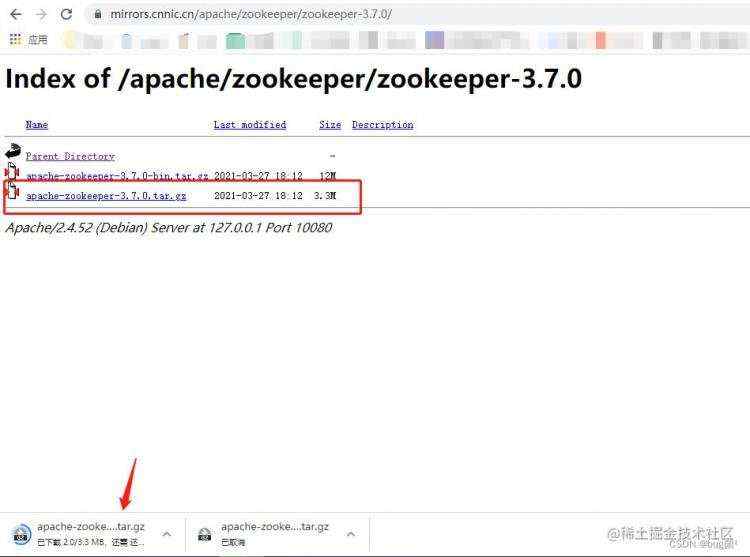
下载完后进行解压,解压到指定的目录下;

然后再将apache-zookeeper-3.7.0-bin也一并下载,进行解压完后,将目录下的lib文件夹复制到apache-zookeeper-3.7.0主目录下:
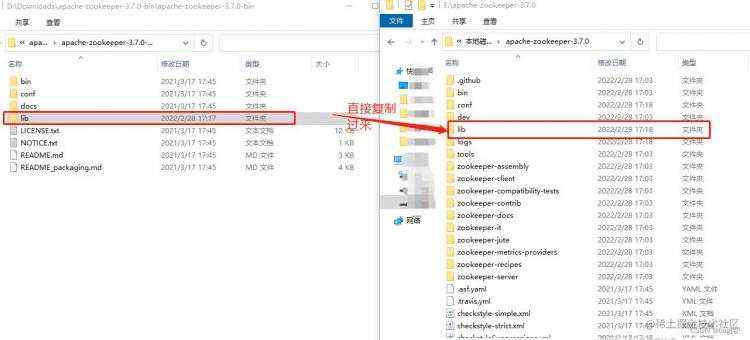
否则后续启动肯定会报错。

修改zoo_sample.cfg 文件名(./conf) 为 zoo.cfg

同样再编辑它指定日志位置,具体配置文件如下:(这里使用notepad++小绿本进行编辑);我这里是指定在同级目录下了。这个你根据实际情况而定。
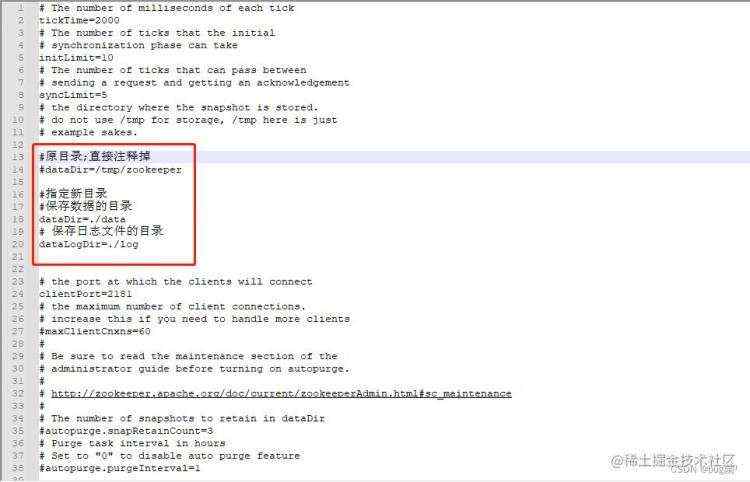
具体添加如下:仅供参考复制。
#原目录;直接注释掉
#dataDir=/tmp/zookeeper
#指定新目录
#保存数据的目录
dataDir=./data
# 保存日志文件的目录
dataLogDir=./log
进入到bin目录,并且启动zkServer.cmd,这个脚本中会启动一个java进程。
如果你们遇到这个报错,请看上边第2点zookeeper解压。报错是因为找不到类包缺少lib这个jar包文件夹,所以你得下载bin包并把lib依赖都复制过来。
输入如下命名进行启动zookeeper
zkServer.cmd
具体启动如下:

正常启动截图:
 再启动后jps可以看到QuorumPeerMain的进程。直接win+R 输入cmd然后再输入如下命令即可进行查询。
再启动后jps可以看到QuorumPeerMain的进程。直接win+R 输入cmd然后再输入如下命令即可进行查询。
启动命令如下:
jps -l -v
 启动客户端连接一下:
启动客户端连接一下:
进入到/bin目录下,执行如下命令:
zkCli.cmd 127.0.0.1:2181

如上可以看到, zookeeper启动ok。至此,zookeeper就安装完成啦。
所以我们再来启动一下kafka看看,是否还会跟刚才一样报错。
切记不要关zookeeper启动服务小黑窗,也就是你执行那串命令的窗口,若是关了你再重新启动即可。
zkServer.cmd
kafka启动成功截图:

#配置kafka 服务器
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。 batch-size: 16384 # 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
package com.example.demo.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* topic初始化
*
* @author luoYong
* @version 1.0
* @date 2022/2/28 17:39
*/
@Configurationpublic class KafkaConfig
/**
* 创建一个名为topic.test的Topic并设置分区数为8,分区副本数为2
*/
@Bean public NewTopic initialTopic()
return new NewTopic("topic.test", 8, (short) 2);
package com.example.demo.component.kafka;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFutureCallback;
/**
* kafka消息发送端
*
* @author luoYong
* @version 1.0
* @date 2022/2/28 17:40
*/
@Component
@Slf4j
public class KafkaProducer
@Autowired
private KafkaTemplate
public void send(Object obj)
String obj2String = JSONObject.toJSONString(obj);
// 发送消息
kafkaTemplate.send("topic.test", obj).addCallback(new ListenableFutureCallback
@Override
public void onFailure(Throwable throwable)
// 发送失败的处理
log.info("topic[] 生产者 发送消息失败[]", "topic.test", throwable.getMessage());
@Override
public void onSuccess(SendResult
// 成功的处理
log.info("topic[] 生产者 发送消息成功[]", "topic.test", stringObjectSendResult.getProducerRecord().value());
);
package com.example.demo.component.kafka;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
/**
* 消息接收端-支持多端消费
*
* @author luoYong
* @version 1.0
* @date 2022/2/28 17:42
*/
@Component@Slf4jpublic class KafkaConsumer
@KafkaListener(topics = "topic.test", groupId = "topic.group1")
public void topicTest(ConsumerRecord record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic)
Optional message = Optional.ofNullable(record.value());
if (message.isPresent())
Object msg = message.get();
log.info("客户端 A 消费了: Topic[] Message[]", topic, msg);
ack.acknowledge();
@KafkaListener(topics = "topic.test", groupId = "topic.group1")
public void topicTest1(ConsumerRecord record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic)
Optional message = Optional.ofNullable(record.value());
if (message.isPresent())
Object msg = message.get();
log.info("客户端 B 消费了: Topic[] Message[]", topic, msg);
ack.acknowledge();
/**
* @author luoYong
* @version 1.0
* @date 2022/2/24 17:02
*/
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class KafkaTest
@Autowired
private KafkaProducer kafkaProducer;
@Test
public void testSendMsg()
String msg = "hello";
kafkaProducer.send(msg);

... ...
ok,以上就是我这期的全部内容啦,如果还想学习更多,你可以看看我的往期热文推荐哦,每天积累一个奇淫小知识,日积月累下去,你一定能成为令人敬仰的大佬的。好啦,咱们下期见~
springboot系列(二):yaml、properties两配置文件介绍及使用
如果还想要学习更多,小伙伴们可关注bug菌专门为大家创建的专栏《springboot零基础入门教学》,从无到有,从零到一!希望能帮助到更多小伙伴们。
我是bug菌,一名想走👣出大山改变命运的程序猿。接下来的路还很长,都等待着我们去突破、去挑战。来吧,小伙伴们,我们一起加油!未来皆可期,fighting!
最后送大家两句我很喜欢的话,与诸君共勉!
☘️做你想做的人,没有时间限制,只要愿意,什么时候都可以start。
🍀你能从现在开始改变,也可以一成不变,这件事,没有规矩可言,你可以活出最精彩的自己。

💌如果文章对您有所帮助,就请留下您的赞吧!(#^.^#);
💝如果喜欢bug菌分享的文章,就请给bug菌点个关注吧!(๑′ᴗ‵๑)づ╭❤~;
💗如果对文章有任何疑问,还请文末留言或者加群吧;
💞鉴于个人经验有限,所有观点及技术研点,如有异议,请直接回复参与讨论(请勿发表攻击言论,谢谢);
💕版权声明:原创不易,转载请附上原文出处链接和本文声明,版权所有,盗版必究!!!谢谢。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有